Um transformador, na lembrança popular, era [ainda é] a série de filmes [Transformers, bit.ly/3Qp97cu] onde objetos inanimados, inconscientes e -só por acaso- alienígenas, que existiam na Terra no formato de veículos, se transformam em humanóides com superpoderes capazes de defender o planeta de ameaças indizíveis, representadas, aliás, por outros transformers. Hoje, um transformador é um modelo de aprendizado profundo usado principalmente para processamento de linguagem natural e visão computacional. Este post é sobre os últimos transformadores e as mudanças potencialmente radicais que eles estão causando no espaço-tempo digital: transformers têm o potencial de mudar uma miríade de facetas da construção, aplicação e uso de sistemas de informação em todos os mercados, de ciência, educação, saúde e mídia a indústria, varejo e relacionamento com e entre as pessoas. Qualquer post é muito pequeno para tratar tudo isso… e este também. Considere-o assim. E leia os links. Não foram escolhidos por acaso.
Em cada um dos parágrafos abaixo, a primeira frase, em negrito, é o título do post, artigo ou paper usado como base para escrever o parágrafo e o[s] seguinte[s], se eles não começarem com uma frase em negrito [seguido do link para o texto de origem]. O resto é conversa. Simbora.
Grandes modelos linguísticos estão transformando educação, ciência e sociedade [stanford.io/3CzAJ8V]. Grandes modelos linguísticos [LLMs] são uma classe de algoritmos de inteligência artificial [detalhes aqui no blog, em… bit.ly/3FJMKdS e adicionalmente aqui: bit.ly/3Gr5A91]. O modelo mais conhecido, GPT-3, tem 175 bilhões de parâmetros e foi treinado usando 570 gigabytes de texto. E não é o maior modelo linguístico que há por aí [bit.ly/3ir1upk]. Com todos os problemas que ainda têm e que provavelmente terão por muito tempo, LLMs geradores de texto e imagem estão criando um novo espectro de uso de algoritmos de IA e em todas as facetas da sociedade.
Para tratar só um exemplo de seu impacto -e da reação a ele- processos -em educação- que dependem de uma visão antiquada de aprendizado, baseada em perguntas e respostas… de repente se tornaram quase completamente obsoletos. O que não significa que deixarão de ser usados por décadas. Afinal de contas, a disponibilidade de livros e alfabetização, em larga escala, deveria ter pelo menos reduzido o uso das aulas puramente expositivas e da “decoreba”. Mas não. Elas continuam aí, e ainda vão continuar por muito tempo, na maioria das escolas. E isso vai ser um problema, porque as escolas e universidades inovadoras vão se aproveitar destas novas plataformas para dar um salto no aprendizado e preparar seus alunos para usar os LLMs em suas jornadas de aprendizado e carreiras.
Nova York bloqueia acesso a ChatGPT nas escolas [ab.co/3ICMrU6]. ChatGPT, uma manifestação conversacional de GPT-3.5, pode escrever texto que muitos -inclusive professores experientes- vão confundir com obra do engenho e arte humanos. Os alunos, que têm muito mais tempo do que os professores para descobrir o que fazer com a coisa, já entenderam isso. E a cidade de Nova York, pra não ficar parada, resolveu bloquear ChatGPT nas escolas, num esforço para evitar o uso da ferramenta, pelos alunos, para produzir redações, ensaios e “respostas” às perguntas dos professores. A decisão de NYC, maior distrito escolar dos EUA, pode influenciar redes de ensino público em todo país.
Mas vai adiantar de quê?… Imagine-se na Idade Média, num lugar onde não houvesse papel, pena e tinta. De repente, aparecem os três e alguém que já sabe ler e escrever e começa a habilitar muito mais gente a fazer o mesmo. Daí pra aparecem livros e versões alternativas das escrituras é só um salto no espaço-tempo social; mesmo que leve décadas, nos séculos anteriores não havia acontecido nada. Tecnologia -como escrita, papel, pena e tinta, acima- liberta. E, como NYC interpretou, ameaça o status quo. Não é à toa que, no início da revolução da informação -com a prensa de Gutenberg, de 1454 em diante- e quando tinha poder para tal, a igreja católica controlava a publicação de livros com seu imprimatur [bit.ly/3WUfGWM]. Smartphones, que têm o potencial de libertar os alunos das paredes das salas de aula, ainda são banidos em boa parte das escolas do mundo, sob a hipótese de que sua proibição diminui bullying e a dispersão dos alunos [bit.ly/3GPupfZ]. Mas o que diz a ciência? Que não há nenhum impacto da proibição de celulares no desempenho dos alunos [bit.ly/3Cw1eMI]. O caso, claro, não é resolvido por ciência nem tecnologia, mas por uma combinação de hábitos, costumes, preconceitos, políticas e… aprendizado. Um dia, a escola aprende que não adianta proibir. Nem smartphones, nem ChatGPT, nem… livros. Nenhum deles.

Novos algoritmos linguísticos podem reforçar as desigualdades e a fragmentação social [bit.ly/3GpiYKz]. Umas escolas vão mudar e aceitar o futuro mais rápido do que outras. Em muitos casos, países inteiros vão sair na frente, outros vão ficar na lata de lixo da história. Os alunos que não estiverem nas escolas que vão mudar -talvez radicalmente- seus métodos vão se atrasar. Não vão dominar as tecnologias que talvez seriam essenciais para sua empregabilidade presente e futura. No caso de LLMs, é preciso aprender a interagir com sistemas, no plural, e entender seus limites e suas possibilidades. Isso, em si, deveria ser parte da educação contemporânea, já. Assim como lidar com mapas digitais deveria ser parte do aprendizado de qualquer aluno do ensino fundamental. Sem falar que máquinas de busca [que correm o risco de serem substituídas por agentes conversacionais, ou “máquinas de respostas”, baseadas em LLMs] deveriam ser aprendidas até antes da escola formal.
O fosso que separa quem tem educação de classe mundial de quem não tem vai se tornar ainda mais largo e profundo. É possível que a exclusão aumente muito; porque um número muito grande de organizações de educação [e outras] vai reagir aos LLMs e proibirá seu uso -por muito tempo. Professores, muitos, vão se sentir tão atacados quanto Sócrates, que culpava a escrita por enfraquecer a necessidade e o poder da memória e permitir a pretensão de compreensão, em vez da verdadeira compreensão. Dependesse do grande filósofo, ainda não teríamos nem escrita, tampouco livros. Sem ter acesso a LLMs e ao aprendizado sobre seu uso, alunos de escolas atrasadas [eu diria, na maioria dos casos, públicas, da periferia…] ficarão ainda mais retardados em relação a seus pares nas escolas de elite.
Ainda por cima, a minimização e|ou deturpação da representação de comunidades marginais no treinamento de LLMs pode amplificar as narrativas de quem já domina o discurso e os recursos econômicos e sociais, aumentando o grau de exclusão da periferia. O potencial de uso -em larga escala- de LLMs para realizar tarefas que parecem cognitivas, mas que na verdade são mesmo de pergunta-resposta ou copia-e-cola, deverá reorganizar e deslocar trabalho, poderá aumentar desigualdade e levar, como consequência, ao aumento da fragmentação social.
Grandes modelos linguísticos ampliam o alcance da IA nos mercados e empresas. [bit.ly/3Zkg9TS]. “LLMs são flexíveis e capazes de responder a perguntas em domínios complexos, traduzir idiomas, compreender e resumir documentos, escrever histórias e código”, segundo Bryan Catanzaro, da Nvidia. Um dos problemas que LLMs atacam é o de síntese de conteúdo [texto, imagem, vídeo, áudio] a partir de qualquer conteúdo, apesar de que, no momento, estamos quase só vendo LLMs treinados por texto e imagens sintetizarem texto e imagem. Dá pra automatizar -trivialmente- parte da escrita de código, até porque os textos de treinamento são linguagens formais e a síntese, idem. Pela mesma razão, é possível aumentar muito a performance dos processos de descoberta de novos medicamentos, porque proteínas, DNA, RNA, estruturas moleculares e sequências de aminoácidos e nucleotídeos podem ser muito complexos, mas são sistemas formais [e sempre podem ser descritos por texto, formal]. Código e DNA têm regras muito mais simples para sua expressão e compreensão do que o universo do texto lúdico, humano, como romance e poesia.
LLMs podem ser usados para reduzir riscos e identificar fraudes, analisar opiniões e evitar, mitigar e tratar reclamações de clientes, aumentar automação de processos de todo tipo. De fotografia computacional a educação, passando por experiências interativas para usuários móveis, LLMs podem ser o ponto de partida para milhares de startups tentando descobrir os saltos, em soluções e modelos de negócios, da atual geração plataformas digitais para uma de suas evoluções, as plataformas artificiais.
Transformadores mudarão radicalmente nossa forma de interagir com máquinas computacionais [bit.ly/3GqBu5w]. Não exatamente agora, mas daqui a algum tempo. Por que? Até aqui precisávamos de um ou mais especialistas em computação, mais especificamente em programação, para fazer com que computadores “entendessem” o que queríamos que eles fizessem. Não vamos deixar de escrever código; as partes mais complexas dos sistemas de informação continuarão sendo pensadas, desenhadas e escritas por humanos -como são os LLMs. Mas, como já dissemos, código é texto; treinado por código, em contexto, um LLM de propósito específico vai acelerar muito a escrita de código e aumentar dramaticamente a produtividade de quem entender como usá-lo para tal.
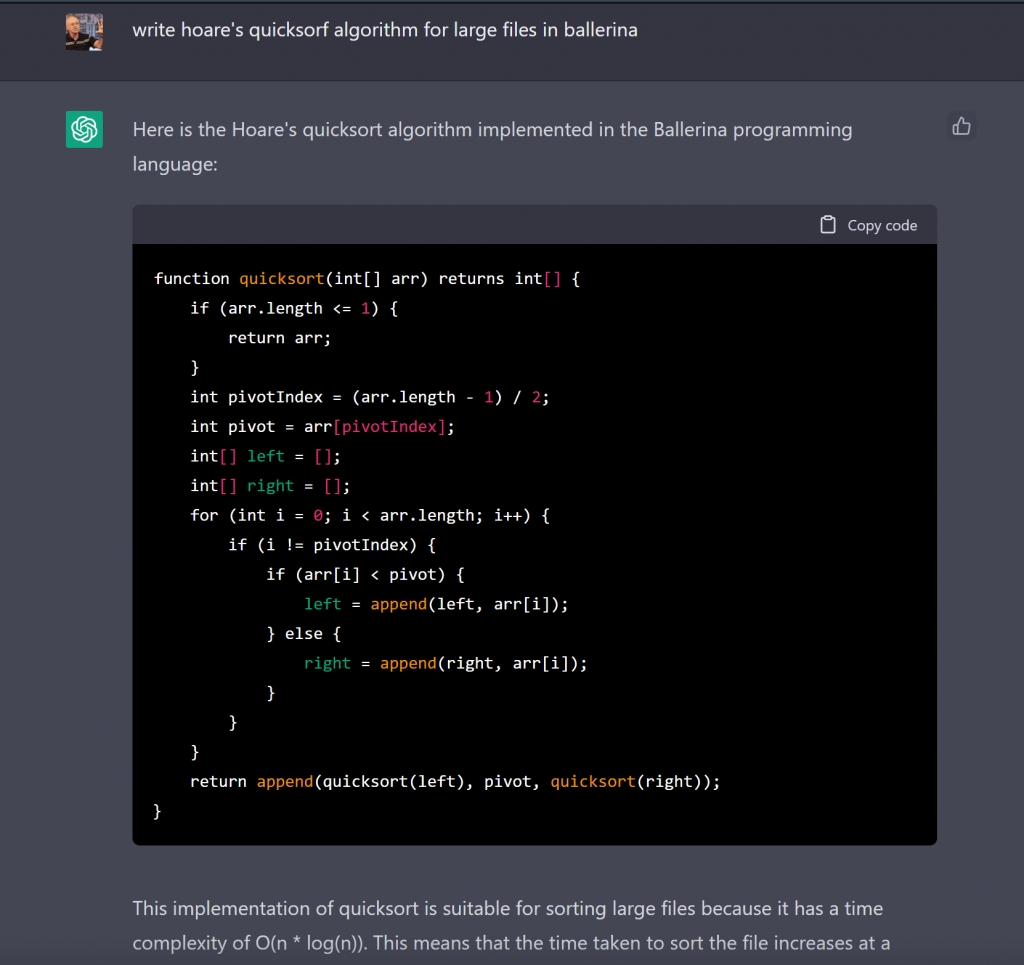
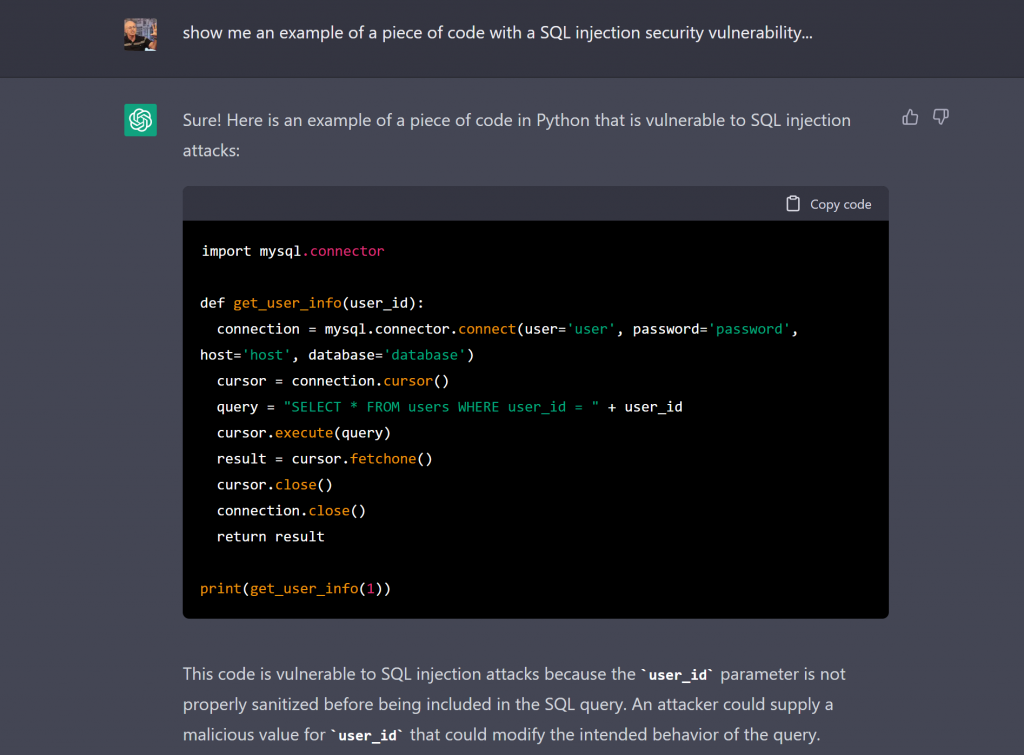
No outro lado da moeda, mesmo LLMs genéricos, como ChatGPT, “entendem” o suficiente de código para responder perguntas sobre algoritmos, código e linguagens de programação de propósito específico para responder perguntas que demandariam [no passado recente] pelo menos algum estudo equivalente a parte de uma graduação em computação [veja imagem acima] ou um conhecimento razoável do que são ambientes computacionais como bancos de dados e sua segurança, na prática [veja imagem abaixo].
LLMs são sistemas linguísticos e, claro, terão imenso impacto no tratamento de linguagem. E linguagem natural, cuja dificuldade de tratamento no passado sempre foi um grande empecilho ao desenho de sistemas computacionais minimanente complexos, por muita gente. Sem codificar, não se conseguia fazer nada. As interfaces eram projetadas para tecnologia, não para humanos. LLMs mudam o jogo, ou pelo menos a parte menos complexa dele: estamos conversando com máquinas de forma imediata, ampla e simples, na língua que falamos. Como mágica, o Babel fish de Douglas Adams saiu do aquário e está em toda a rede [bit.ly/3ZocQv2]. Conversações fluentes com dispositivos habilitados por computação devem se tornar a norma e isso vai redefinir a interação pessoas-máquinas nas próximas décadas.
Devemos ter cuidado sobre como falamos de grandes modelos de linguagem [bit.ly/3XcmbEa]. Por décadas, personificamos dispositivos e aplicativos com verbos como “pensar”, “conhecer” e “acreditar”. Na maioria dos casos, tais descrições antropomórficas são inofensivas. Mas ao falar sobre LLMs, sistemas que imitam “muito bem” o comportamento humano, apesar de serem fundamentalmente diferentes da mente humana, a situação muda muito. Segundo Murray Shanahan, professor de Cognitive Robotics do Imperial College London, “LLMs podem ser semelhantes aos humanos, e eles melhoram rapidamente. Depois de interagir com eles por um tempo, é muito fácil começar a pensá-los como entidades com mentes como a nossa. Mas eles são uma forma alienígena de inteligência, e ainda não os entendemos completamente. É preciso cautela ao incorporá-los aos assuntos humanos”. Shanaham continua: “Talvez tenhamos que interagir e conviver com LLMs por muito tempo antes de descobrir como falar sobre eles. Até lá deveríamos resistir a tratá-los antropomorficamente.” Porque os riscos envolvidos não são triviais.
Os grandes riscos de grandes modelos de linguagem [bit.ly/3k3h5Mp]. O primeiro grande risco é que LLMs não estão preparados para lidar com questões éticas, morais, filosóficas e da natureza humana em geral. Será que um dia estarão? Eu acho que… um dia, quem sabe? O segundo risco, que multiplica o primeiro, vem do efeito ELIZA.
ELIZA, um dos primeiros sistemas de processamento de linguagem natural [criado entre 1964 e 1966, bit.ly/3XgDX9f], simulava conversas e dava aos usuários uma ilusão de compreensão do diálogo por parte do programa, que não tinha, obviamente, a menor condição de entender o que estava capturando dos usuários e produzindo como resposta… mas era tratado por muitos como se estivesse. O efeito ELIZA, em computação, é a tendência humana de assumir inconscientemente que os comportamentos do computador são análogos aos comportamentos humanos.
Com LLMs e suas capacidades, o efeito ELIZA é amplificado, a ponto de um engenheiro de software especialista em IA acreditar que um LLM [LaMDA, bit.ly/3vPdSCx] seria consciente… o que mostra como quase todos humanos podem ser crédulos em excesso. LLMs distam de consciência mais do que a Terra de Earendel [bit.ly/3ip5jey] mas, como imitam bancos de dados de interação humana, podem facilmente enganar os incautos.
Os LLMs de hoje já são melhores do que qualquer tecnologia anterior para enganar humanos com suas “conversas”, estão se tornando mais baratos de criar, treinar e rodar e mais fáceis de usar. A adoção generalizada de LLMs parece que será exponencial, apesar de suas muitas e óbvias -pelo menos para os especialistas- falhas.
ChatGPT é observado com a respiração suspensa [bit.ly/3GtZZib]. Desde Google [e o algoritmo pagerank, que mudou a forma de indexar e buscar a web, bit.ly/3Bt6obI], Facebook [e o algoritmo social graph, bit.ly/3itu7Cf] e Bitcoin [e toda a arquitetura algorítmica por trás do peer-to-peer electronic cash system, bit.ly/3vQS0a4], não havia nenhuma novidade tão radical e a chamar tanta atenção -porque causa tanto impacto imediato e potencial- quanto LLMs. ChatGPT é a linha de frente, a vitrine de uma gama inteira de plataformas baseadas em algoritmos de inteligência artificial.
Explorando o potencial e as limitações do ChatGPT no mundo corporativo [bit.ly/3CzCIKp]. A primeira parte do texto do link acima foi feita por ChatGPT, bem como o início do texto [no blog, bit.ly/3FJMKdS] Inteligência Artificial e Grandes Algoritmos. Uma enormidade de exemplos como estes foi publicada nos últimos meses, basicamente para mostrar [o do cabeçalho faz isso, em mínima parte] as possibilidades do uo de LLMs nos negócios. É possível aproveitar IA criativa, incluindo ChatGPT, conhecendo suas limitações [bit.ly/3VW4vM5]. Para criar texto, extrair e sumarizar informação a partir de textos de entrada; analisar características de e melhorar textos; criar imagem a partir de texto; escrever código; transformar texto em código, tratar imagem, vídeo… controlar robôs, e por aí vai. As possibilidades são muitas. Infinitas, na realidade.
Além das palavras: LLMs expandem horizonte de IA [bit.ly/3GQwvfI]. Fato. LLMs criaram todo um novo universo de aplicação de IA… por pessoas que não precisam de qualquer treinamento sobre como usar um engenho baseado em IA extremamente complexa -mas têm que pelo menos aprender prompt engineering [bit.ly/3IAQHU5]. A coisa é nova, está crescendo em complexidade e alcance seguindo uma espécie de Lei de Moore para IA. Tem um mundo de oportunidades, porque o investimento em IA ainda é muito pequeno nas empresas estabelecidas e na criação de novos negócios, e porque quase certamente os impactos de todas as formas de IA, incluindo LLMs, será transformador em si.
A transformação do trabalho cognitivo, que parecia a salvo nos processos mais amplos de automação, informatização e robotização da economia, vai impactar radicalmente as pessoas, as organizações, o emprego… quase certamente será o ponto de partida para mais uma onda de inovação muito intensa da revolução da informação, a base definida em código, e sempre mutante, para a economia do conhecimento.
É preciso, aqui, recaracterizar o significado de radicalmente. Segundo Wittgenstein, às vezes é preciso tirar uma expressão da língua e dar-lhe uma limpada antes dela voltar a circular. Este é o caso de radical. Atribuída a tudo, acaba significando nada, e às vezes algo que não se quer dizer sobre alguma coisa. O radicalmente do parágrafo anterior vem de sua ressignificação por Marie-José Mondzain, e embute na radicalidade a “esperança de lá inscrever o desejo e as condições para uma transformação, devolvendo à palavra aquilo a que ela pertence, ou seja, sua beleza virulenta e sua energia política“. Sem ter espaço, em sua semântica, para o niilismo ou extremismo, uma “verdadeira radicalidade, indissociável da força irresistível do riso e da alegria” [bit.ly/3jWv9a9].
A grande transformação dos transformadores será radical.