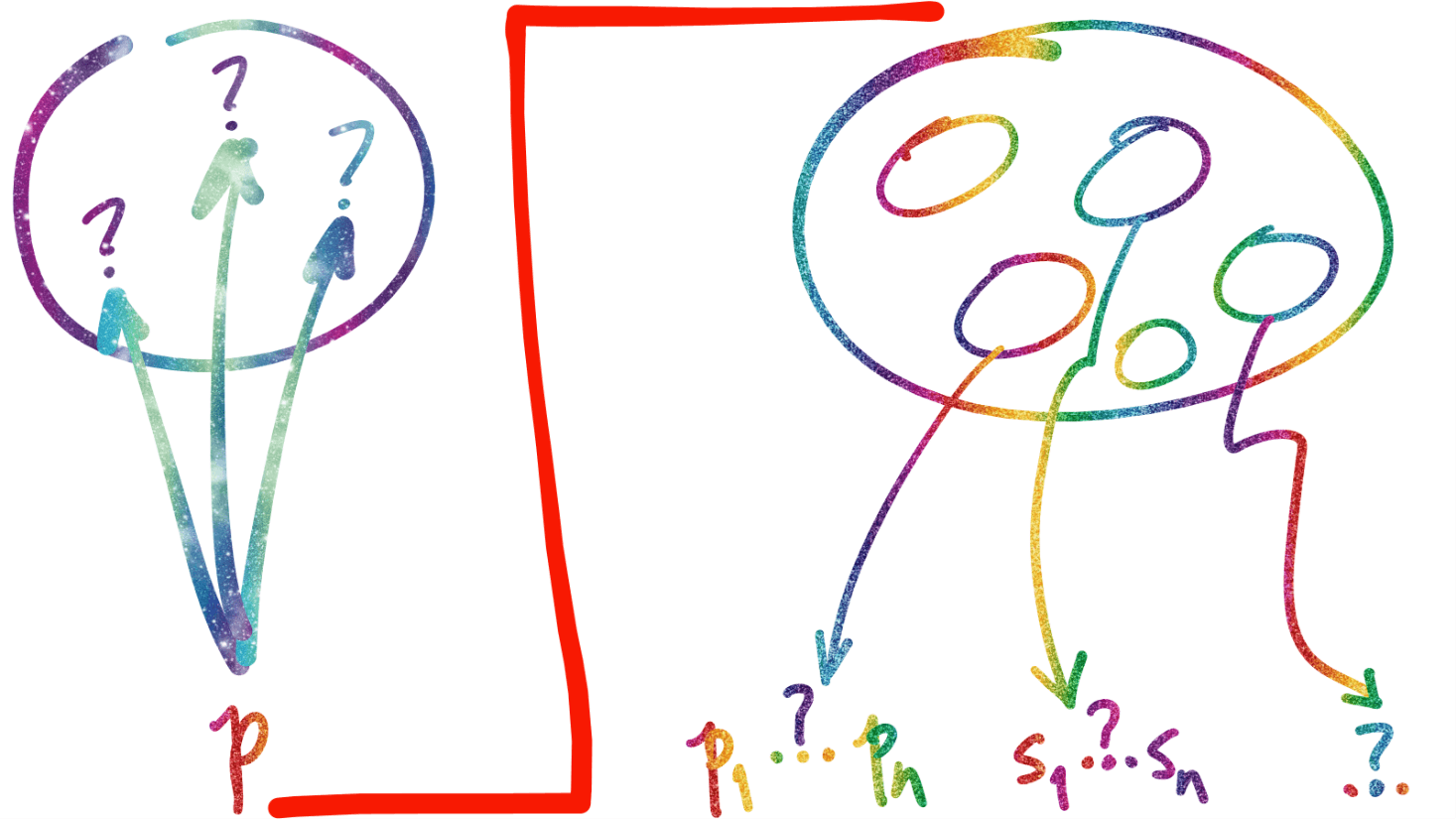Mas IA, de onde vem, pra onde vai?…
No futuro, há três tipos de inteligência:
individual, social e artificial.
E as três já são dimensões da performance humana, agora.
”I propose to consider the question ‘Can machines think?’”, é a primeira frase de Computing Machinery and Intelligence, artigo de Alan Turing na revista Mind [outubro de 1950, tinyurl.com/yc28s45x]. Ela pode ser considerada o ponto de partida que nos trouxe ao frenesi sobre inteligência artificial, e suas implicações para a humanidade, que assola da mesa do bar ao altar, hoje. Lá, Turing diz que imitar uma mente humana com uma máquina [inteligente] envolve… 1. partir de um estado inicial da mente [como o do nascimento…]; 2. educá-la [formalmente] até um estado equivalente a um adulto e 3. adicionar outras experiências [que não podem ser descritas como educação].
Assumindo que seja isso, será que já temos a combinação de 1 + 2 + 3 agora? Minha melhor hipótese é que não temos, ainda. Mas que, algum dia [quando?…] teremos. A comparação de Turing é que o processo envolvido em 1 + 2 + 3 se parece com a evolução [das espécies] e ele dizia, ainda, que …one may hope, however, that this process will be more expeditious than evolution; the survival of the fittest is a slow method for measuring advantages. Com gerações inteiras de máquinas [inteligentes?] evoluindo por dia [horas? minutos?…], é de se esperar que não tenhamos que esperar centenas de milhares ou [centenas de] milhões de anos para que 1 + 2 + 3 entregue alguma máquina verdadeiramente inteligente.
Mas todo mundo que tentou prever quando isso iria acontecer, errou, e por muito, até agora [Technological singularity, tinyurl.com/2c9nvnfp]: se dependesse de I. J. Good, o primeiro a formular a hipótese da singularidade em 1965, já teríamos inteligência artificial geral dentro de uma máquina desde 2000. Hoje, há quem diga que o prazo é 2050 [ao custo de míseros US$1 trilhão em capacidade computacional] mas outros garantem que não rola antes de 2300 [An executive primer on artificial general intelligence, tinyurl.com/2bv5jqex], porque a agenda de problemas a resolver [percepção sensorial, engajamento social e emocional, autonomia, criatividade, resolução de problemas… sem falar dos problemas computacionais] é grande, complexa, e… nós ainda nem sabemos bem como os cérebros humanos fazem isso.

Voltando a Turing, ele faz muito mais perguntas do que responde [completamente], no artigo, e continua em aberto, até hoje, o que é [exatamente] inteligência, memória, isso sem falar em mente e consciência, e por aí vai. Só pra ter uma ideia, parece que estamos chegando à conclusão de que o cérebro humano armazena uns 2.500 Terabytes [Nanoconnectomic upper bound on the variability of synaptic plasticity, tinyurl.com/27jzls49]. Se usássemos o cérebro pra gravar informação como vemos, por exemplo, isso daria umas 20 horas de vídeo, na resolução do olho humano.
Mas, durante uma vida, capturamos mais de 400.000 horas de “vídeo” [Can a human brain hold your life experience?, tinyurl.com/2y384ckq], e isso só com um sentido! A “memória” do cérebro é muito mais esperta do que um mero sistema de armazenamento e recuperação de informação, tem capacidades [de compressão, abstração…] não triviais e não completamente explicadas, apesar de seus limites estritos de processamento de informação [Capacity limits of information processing in the brain, tinyurl.com/27ncofpx]. Mas o cérebro humano é muito mais sofisticado do que grandes modelos linguísticos como a família GPT, começando pelo básico: LLMs não conectam as palavras [textos, imagens, vídeos] que sintetizam com o mundo aqui fora [Brain in a Vat: On Missing Pieces Towards AGI in LLMs, tinyurl.com/25ssj97a].
Yangmingzi [1472-1529, tinyurl.com/259xrbqs], interpretando Mengzi, dizia que… aqueles que “sabem”, mas não fazem, simplesmente ainda não sabem. Como um ditado, ouvi esse aforismo durante toda minha carreira na universidade, e de forma depreciativa: quem sabe, faz; quem não sabe, ensina. Sempre achei que deveria ser… quem sabe, faz; quem não sabe, aprende, conectando experiência e educação como John Dewey propôs magistralmente em 1938 [tinyurl.com/244elalw]. Esse é exatamente o caso dos LLMs, que não sabem… nada. Mas… como poderiam vir a saber? Melhor ouvir Turing, de novo?…
Uma releitura contemporânea de Turing, usando três princípios muito correlacionados ao do fundador da computação, está em Minedojo: Building open-ended embodied agents with internet-scale knowledge, [Fan, L. et al., 2022, tinyurl.com/2lyafnsc], onde o problema tratado é o desenvolvimento de agentes autônomos incorporados que podem atingir desempenho similar ao humano em um amplo espectro de tarefas. Para isso… 1. a arquitetura do agente precisa ser flexível [para executar qualquer tarefa em ambientes abertos] e escalável [para converter grandes bases de conhecimento em insights acionáveis]; 2. deve haver uma base de conhecimento prévio em grande escala [para facilitar aprendizado em ambiente aberto] e 3. o ambiente em que o agente atua precisa permitir uma variedade ilimitada de objetivos abertos [i.e., não definidos a priori] para que o agente se desenvolve [em potencial, ilimitadamente]. Esse 1 + 2 + 3 aí é “o mesmo” de Turing, lá no começo do texto.
Linxi Fan e co-autores criaram um framework pra fazer isso em Minecraft [veja o link acima] e a base de conhecimento [o item 2, acima] tem mais de 730 mil vídeos narrados de gameplay, [cerca de 300 mil horas] e 2,2 bilhões de palavras na transcrição para o inglês. Tal tamanho de esforço muda, em si, o que a gente costumava chamar de pesquisa científica até algum tempo. Mas… onde isso vai nos levar? Tudo bem que temos tempo, até 2300, pelo menos, pra ter uma inteligência artificial capaz de competir a sério -ou de brincadeira, pode ser ainda melhor- com humanos. Mas vamos chegar lá? Ninguém sabe, mas prevejo que sim, vamos chegar perto, se definirmos o lá com alguma precisão.
E mesmo com uma definição precisa do lá, o caminho é muito difícil. Primeiro, aumentar [muito] a capacidade dos modelos atuais [que muita gente acha que “são” IA…] talvez não nos leve a nada mais do que… modelos maiores, e não muito melhores [veja este e outros argumentos em The shape of AGI: Cartoons and back of envelope, tinyurl.com/22le9okg]. Segundo, é quase certo que impedimentos computacionais fundamentais vão nos deixar pelo menos um pouco longe do lá de várias formas. Quer ver só um?…
Em 2005, Marcus Hutter provou [em Sequential Decisions based on Algorithmic Probability, tinyurl.com/82lyarl] que o comportamento ótimo de um agente que tenta atingir objetivos em um ambiente desconhecido, mas computável [como os agentes de Linxi Fan, acima], é adivinhar a cada passo que o ambiente é provavelmente controlado por um dos programas mais curtos consistentes com todas as interações até agora. Só que não há uma solução geral para este problema, que é o mesmo da complexidade de Kolmogorov, por sua vez vizinho dos problemas fundacionais de Gödel e Turing na computação. Hutter também provou que ao restringir o ambiente a um tempo t e espaço s, há solução em tempo exponencial em s, o que é intratável e por conseguinte inútil na prática. Ou seja… vamos “resolver” o problema com heurísticas e aproximações.
Por que isso importa quando discutimos IA? Porque os agentes de Linxi Fan [em um espaço de voxels… Open-Ended Evolution for Minecraft Building Generation, tinyurl.com/22u6kcu6] têm que resolver o mesmo problema dos LLMs quando calculam a escolha da próxima palavra de uma resposta a um dos prompts que você teclou. Reduzindo muito o que LLMs fazem… eles “simplesmente prevêem a próxima palavra em uma sequência” [veja What Is a Large Language Model, https://tinyurl.com/25akvzbb, para uma explicação simples].
LLMs já têm um grande impacto nas expectativas dos humanos sobre o futuro, e futuro próximo, tipo ontem. Isso não quer dizer que LLMs sejam sistemas inteligentes [Large learning models are an unfortunate detour in AI, tinyurl.com/252nf3m4] ou tenham alguma chance, com o aumento de sua capacidade, de chegar lá [que aqui é inteligência humana, irrestrita]. Melhorar um cágado, e muito, você sabe, não resulta numa águia. Não há nenhum caminho de evolução entre a partida e a chegada.
A performance -impressionante, é verdade- de LLMs numa vasta classe de tarefas hoje realizadas por humanos quer dizer, em sua essência, que humanos não deveriam estar realizando tais tarefas -que não demandam nossas capacidades cognitivas mais sofisticadas como deveriam [veja, por exemplo, Attention Control: A Cornerstone of Higher-Order Cognition, tinyurl.com/227bf7n9]. E não que LLMs têm características iguais à da inteligência humana, ou que são “inteligentes como humanos”. Ainda assim, há uma implicação: em muito breve, muitos humanos que estão realizando tais tarefas serão substituídos, pelo menos em parte, por LLMs.
Dito isto, LLMs são certamente um grande passo para a área de inteligência artificial, mas um pequeno passo para a humanidade no complexo e escarpado caminho até, pelo menos 2300.