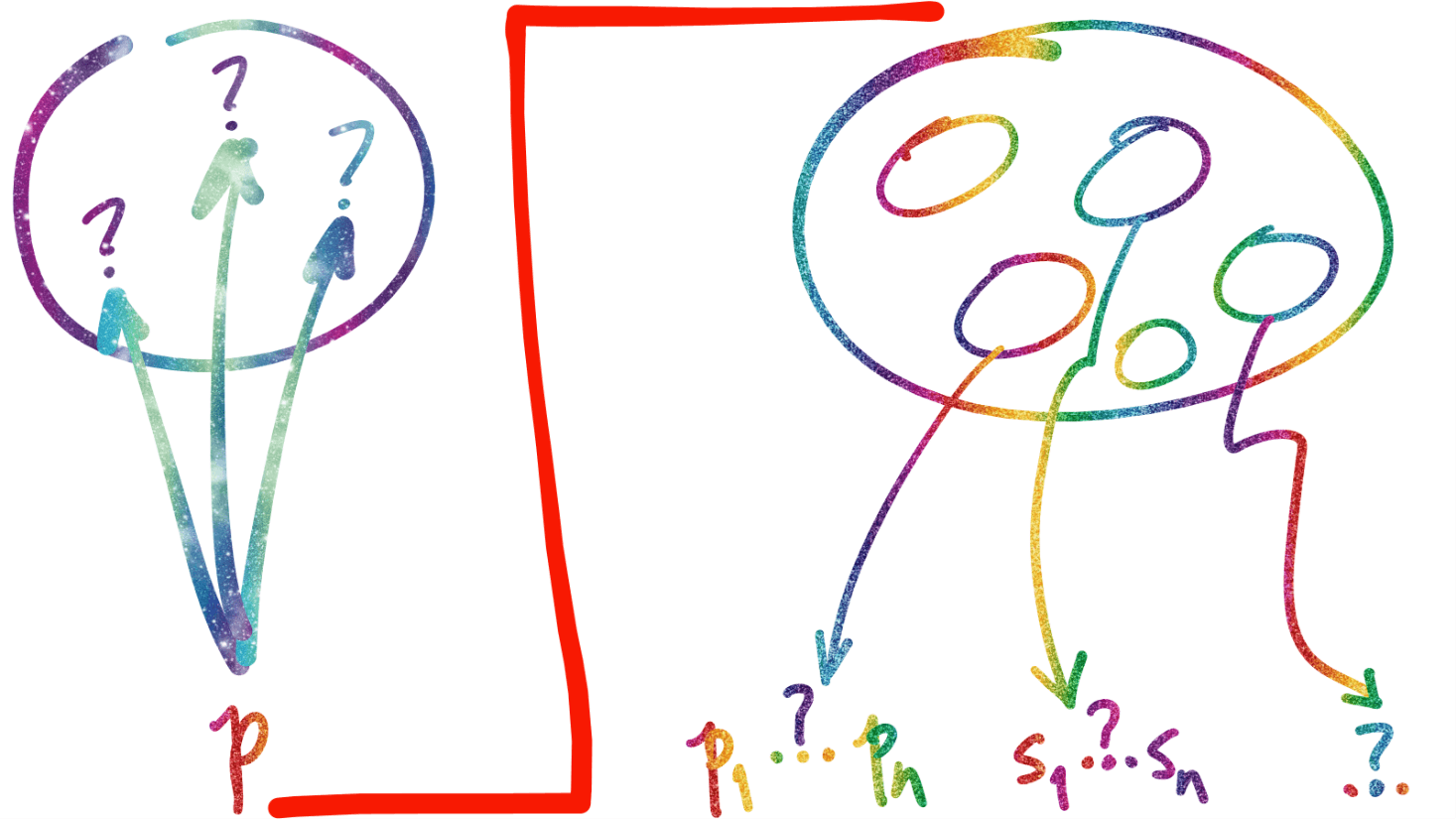uma boa parte da história que conhecemos não vem de fontes oficiais mas das anotações e observações do que poderíamos chamar de “pessoas comuns”, que registraram o cotidiano ao seu redor, no seu tempo, mostrando como a vida e os acontecimentos afetaram seu dia-a-dia. são indivíduos registrando o seu ciclo de vida de informação.
no mundo digital, na sociedade da informação, onde não se manda mais cartas “físicas” –a última que mandei não chegou ao destinatário-, há um número de riscos bem claros de muito pouca informação sobreviver aos seus criadores, a menos que estejam a cargo de alguma instituição.

não se trata só das contas e repositórios correspondentes nas redes sociais e blogs, que se tornarão inativas e que serão removidas, por não estarem sendo utilizadas vários anos depois da morte de seus autores. trata-se da morte, propriamente dita, de tais repositórios: num crime contra a a história da informação, yahoo resolveu tirar geocities do ar em outubro passado, quando o site ainda estava entre os vinte mais populares da web, em tráfego. um grupo de historiadores conseguiu copiar mais de um terabyte de dados do site que yahoo comprou dez anos antes por três bilhões de dólares mas que, segundo os críticos, “nunca entendeu”.
os geocities de hoje em dia são faceBook, orkut, mySpace, hi5, flickr [outro site de yahoo…], twitter, os repositórios onde estão nossos blogs e, de resto, mesmo para quem escreve a soldo, os noticiosos online para quem trabalhamos. tudo o que eu e mais um mundo de gente fez para a revista eletrônica NO., no começo da década passada, sumiu de vista. ainda resistiu no ar alguns depois do fechamento da empresa mas, enfim, virou kipple. salvei tudo o que escrevi e botei neste .PDF aqui… mas não é a mesma coisa. falta o contexto, as outras notícias ao redor, as manchetes e até a propaganda, também sinal e testemunha do seu tempo. isso acaba me fazendo ainda mais falta porque o software que publicava a NO. tinha um “túnel do tempo” que criava viagens de volta a um texto de 2001 no contexto do dia em que foi publicado, como se pudéssemos atrasar o relógio para o dia da publicação. o time que fez o software [eu dentro dele…] tinha muito orgulho desta capacidade. mas de que ela serve se o site, pura e simplesmente, sumiu?…
mais interessante ainda é que a informação na web parece ser tratada de forma intrinsecamente extemporânea: entre setembro de 2006 e dezembro de 2007, escrevi uma coluna semanal para o G1; ao todo, foram 66 textos, muitos dos quais fizeram a primeira página do site e outros tantos que continuam absolutamente atuais, posto que não tratavam da última funcionalidade de um aplicativo ou site qualquer. clique no link que leva para o arquivo de textos antigos do G1 e você vai descobrir que… o arquivo inteiro –e não só meus textos- saiu do ar desde junho de 2009, sem deixar rastro. de novo, e não por mero acaso, guardei os meus, que hoje disponibilizo como presente de páscoa neste link. boa leitura. diga-se de passagem, tal tratamento não é um “problema” do G1, mas uma “característica” da vasta maioria dos sites.

como a maioria dos mortais, mas em um outro nível de competência, a british library está preocupada com a sobrevivência das coleções digitais pessoais, e uma de suas ações nesta direção é o digital lives research project [o blog do projeto está neste link], cujo primeiro relatório acaba de ser publicado. pra deixar claro de quem estamos falando, a BL tem preciosidades digitalizadas como este site com dois milhões de páginas de jornais do séc. XIX e os ingleses, seu público alvo primário, são colecionadores natos.
talvez seja mais fácil fazer uma iniciativa como planets [acrônimo para Preservation and Long-term Access through Networked Services] funcionar no reino unido do que no brasil. ou não: como não temos, ainda, um legado digital tão grande quanto o deles, informatizados há bem mais tempo do que nós, bem que poderíamos não perder tanto quanto eles já perderam… se começássemos a agir rapido e direto aos pontos, agora.
os problemas sendo tratados no digital lives research project não não são simples: vão desde a ética e regulação da informação pessoal [infoética] ao estudo da evolução das plataformas digitais de representação de informação, passando por curadoria e administração adaptativa de arquivos digitais pessoais, sistemas de gestão de informação pessoal, usabilidade da informação preservada, catalogação [colaborativa]… em suma, um mundo de preocupações e, possivelmente, técnicas, métodos, processos, padrões, sistemas e modelos de negócio que vão resultar do projeto. muitos dos quais, talvez, vamos acabar adotando e comprando.
em boa parte, é pra isso que servem, também, projetos como este, da british library, e o europeu planets: criar tecnologias que avançam o estado da prática, que resultam na adoção, pelo mercado, de produtos e serviços que resolvem [ou melhoram a solução de] uma classe de problemas.
afinal de contas, seria muito interessante que houvesse um serviço [privado e público] para dar conta de um ciclo de vida de informação pessoal cujo modelo simplificado [!] é mostrado abaixo… de forma que, gerenciando uma linha do tempo de informação que criássemos ou adquiríssemos, tivéssemos como localizar, acessar, manipular, transformar, transferir, compartilhar, guardar e, eventualmente, descartar o que não mais quiséssemos. clique na imagem, que está ilegível, pra pegar o relatório onde você pode vê-la em detalhe. isso vai rolar. quando? vindo de quem? do povo que quer organizar toda a informação do planeta, hoje? talvez não. eles já têm um legado muito grande a administrar… e não conseguem responder a contento questões sobre a ética da informação privada e, em particular, sobre sua segurança e privacidade. é bem provável que as soluções venham a ser compartilhadas, em rede, onde cada um tenha –mesmo- controle sobre seu ciclo de vida de infromação pessoal. mas parece que ainda vamos demorar muito a chegar lá.
isso vai rolar. quando? vindo de quem? do povo que quer organizar toda a informação do planeta, hoje? talvez não. eles já têm um legado muito grande a administrar… e não conseguem responder a contento questões sobre a ética da informação privada e, em particular, sobre sua segurança e privacidade. é bem provável que as soluções venham a ser compartilhadas, em rede, onde cada um tenha –mesmo- controle sobre seu ciclo de vida de infromação pessoal. mas parece que ainda vamos demorar muito a chegar lá.
tomara que, até o futuro chegar, não percamos muita coisa relevante. enquanto isso, vá ler esta parte da história que eu acabei de recuperar, meus 66 textos para o G1…