vivemos em uma economia da informação. disso já não dá mais pra duvidar. e essa informação está codificada em dados, gerados por uma miríade de fontes, em todo o espectro econômico e social. os dados gerados pelo setor público [ou com seus recursos] têm importância especial neste cenário, pois podem servir de base para aplicações de grande impacto para a sociedade. o setor público e seus contratados são o único fornecedor de uma vasta gama de informação, desde dados básicos sobre a economia e geografia até informação meteorológica e de resultados de pesquisa científica financiada com recursos públicos.
via de regra, se o dado gerado com recursos do estado [dentro ou fora de sua máquina] não tem uma ótima razão para ser sigiloso, ele é público. a lei brasileira de acesso à informação diz que órgãos públicos devem observar a “publicidade como preceito geral e o sigilo como exceção” e que devem divulgar “informações de interesse público, independentemente de solicitações”. se, quando e como tal preceito vai ser cumprido em todas as vertentes e níveis de governo, como a prefeitura de taperoá, é outra história. mas pelo menos a cidadania, agora, tem um sustentáculo legal para suas demandas por dados públicos.
mas não basta o dado público ser “do” público, por lei. ele tem que ser “aberto”. e aberto, no caso de dados governamentais, quer dizer mais do que ser visível, ou de haver um link para se ter acesso à fonte. veja que já descarto, de primeira, dados impressos, gravados em CDs ou outros “meios” do passado distante. “aberto” quer dizer [hoje] estar na rede, conectado. uma definição [quase] universalmente aceita diz que os dados governamentais abertos devem ser completos [tudo que não for sigiloso deve ser liberado], primários [dados devem ser publicados da forma que foram gerados ou coletados, e não filtrados ou agregados], atuais [sem o que o valor do dado pode desaparecer], acessíveis [a disponibilização dos dados deve se dar da forma mais ampla possível], processáveis [por máquina, da forma mais simples possível], não discriminatórios [acesso universal, sem que seja necessária identificação ou registro], ter formatos abertos [o formato deve estar no domínio público] e livres de licenças [livres de direito autoral, marcas, etc].
o bom é que esta definição está bem aqui, em português, no portal brasileiro de dados abertos, o dados.gov.br. mas quando você clica no mesmo portal para ver que dados estão “abertos”…
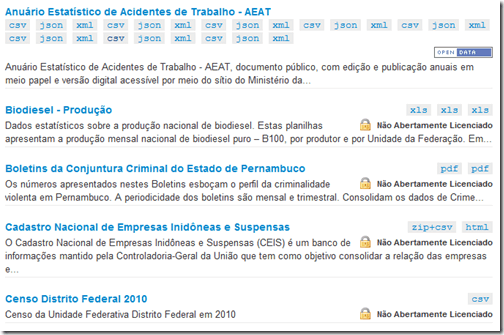
…o tamanho do problema a ser enfrentado pelos fornecedores e consumidores dos dados públicos começa a se tornar aparente. há dados em múltiplos formatos [o que era de se esperar], sem licença aberta [isso não era de se esperar]… e o mais complicado é que a maior parte dos dados disponibilizados está “morta”.
como assim?… dado morto é aquele que, capturado [ou gerado], processado e talvez transformado, é apresentado numa forma estática na qual não é possível extrair, por exemplo, sua origem, composição ou relacionamentos [com outros dados ou fontes de dados, em rede]. exemplo? todo o catálogo de obras do PAC. os dados se referem a dezembro de 2011 e estão “enterrados” em arquivos .csv. é claro, você diria, que os dados são processáveis por máquina. sim, eles atendem um ou dois preceitos da definição de dados abertos, mas sua utilidade é limitada.
há dados que parecem “vivos”, mas não estão… os dados zumbi. aqui, os dados estão “mortos”, do ponto de vista de utilidade prática, mas são “animados” por código a ponto de parecerem “vivos”. um representante é a plataforma lattes do CNPq, registro da academia brasileira e sua produção. os pesquisadores inserem os dados no sistema e eles são enterrados [vivos] nos silos [bancos de dados] da instituição. depois, são “animados” e apresentados em páginas web, como se vivos estivessem. os gestores, questionados pela comunidade acadêmica, dizem estar cumprindo a lei e as normas vigentes. numa leitura superficial, pode até ser o caso e o gestor público pode sempre alegar, a seu favor, que está “fazendo o possível”.

mas o dado zumbi não basta, porque a lei [cap II, art. 7, par. IV] compreende, entre outros, o direito de obter informação primária, íntegra, autêntica e atualizada. a lei estabelece que –se possível- dados públicos devem estar vivos “mesmo”, de acordo com a definição de dados abertos do próprio portal de dados abertos do governo federal. o dado vivo é aquele que está na fonte, que pode ser requisitado e tratado [computacionalmente, de forma não identificada, em ambos os casos…] em estado bruto, sem passar por filtros e sistemas que escondam ou modifiquem características fundamentais. não que se suponha má fé do gestor de dados públicos, longe disso. mas cada fluxo ou banco de dados é passível de uma infinitude de tratamentos, a vasta maioria impensável sem acesso, para exercício, à fonte. e o setor público não tem os recursos e meios para tentar múltiplas formas de tratamento, o que normalmente só acontece se o ciclo de vida da informação for exposto –aberto- em toda sua amplitude.
isso já é feito em larga escala pela iniciativa privada. você não imaginaria a apple ou google escrevendo todas as aplicações para seus smartphones, certo? os app markets, aberturas no ciclo de informação [e programação, no caso] de ambas as empresas, tornaram tal riqueza possível. o mesmo vale para as APIs [interfaces de programação] de google, faceBook, twitter e quase tudo o que está na web, hoje.
quem faz sistemas para a rede tem que pensar e fazer parte da funcionalidade “em casa” e o resto [de preferência a maior parte] “na rua”. aliás, a medida de sucesso de qualquer sistema de informação em rede, hoje, é estar muito mais “na rua” do que “em casa”.
é esta filosofia e entendimento de sistemas e dados abertos que precisamos ter no setor público. ela já é a norma na economia de informação privada. pelo menos na parte dela que vai sobreviver. precisamos migrar nossos dados públicos de mortos para vivos, de preferência sem passar pelos zumbis. porque os últimos não passam de simulacros da verdadeira informação pública e aberta que todos queremos.